インターネット上の情報を探すためのシステム
1.種類
| Google(グーグル) | Google社が開発・提供 テキストによる検索はもちろん、 画像や音声での検索にも対応する AI Overview(AIによる概要)の提供 AIの回答を検索結果に表示する 日本でのシェア80.45% |
| Yahoo!(ヤフー) | Yahoo Japan社が提供 Googleをベースに構築されている 多岐にわたるコンテンツを提供する ポータルサイトニュース、天気、メール、知恵袋等 日本でのシェア9.22% |
| Bing(ビング) | Microsoft社が提供 多種類の検索に対応している テキストや画像、音声等 WindowsのEdge、Office等 様々なMicrosoft製品と連携している CopilotというAI支援機能の提供 検索機能に組み込まれ内容が充実 日本でのシェア8.23% |
2.検索エンジンの仕組み
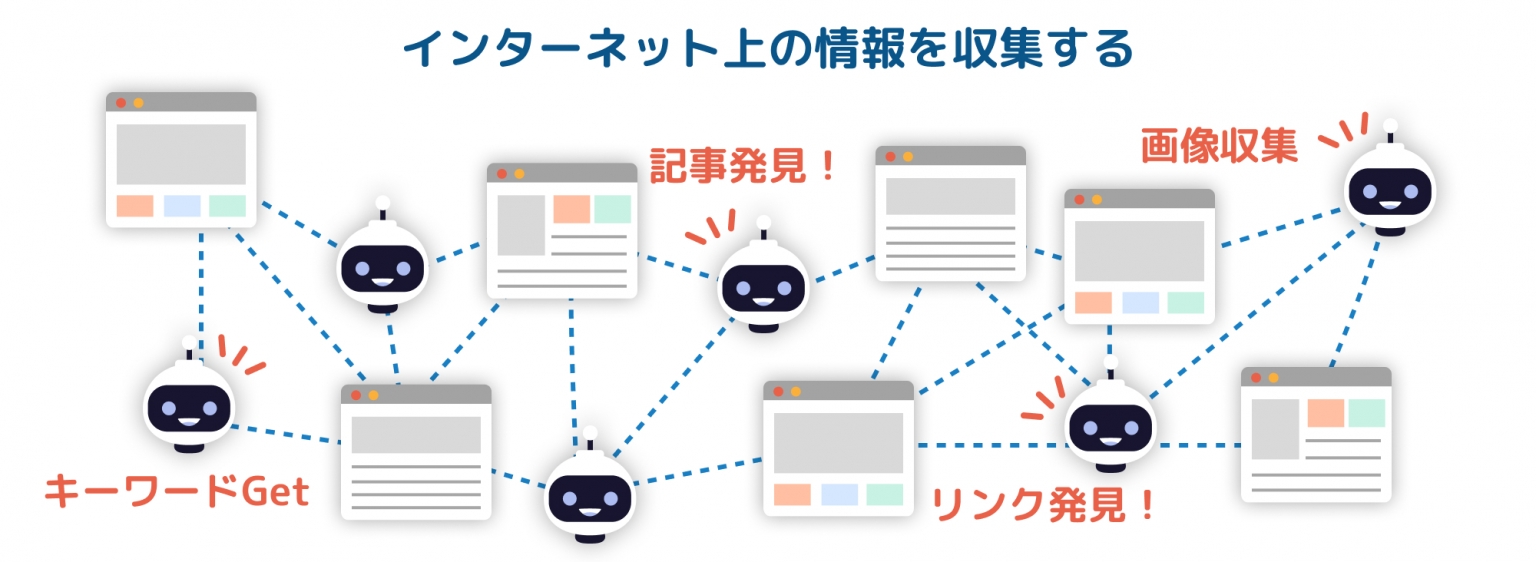
クロール(情報を集める)
インターネット上のWebページを自動で巡回し、情報を収集する
ロボットのようなプログラム(クローラー)が
大量のWebページを素早くチェックする
ログイン情報が必要なページについては、対象外とする
定期的にクロールを行い、新しいページや更新されたページを見つける
ページ本文(テキスト)
タイトル、見出し、メタタグなどの構造に関する情報
内部リンクおよび外部リンク
画像のalt属性やファイル名
robots.txt や sitemap.xml など、クロール可否を示すファイル
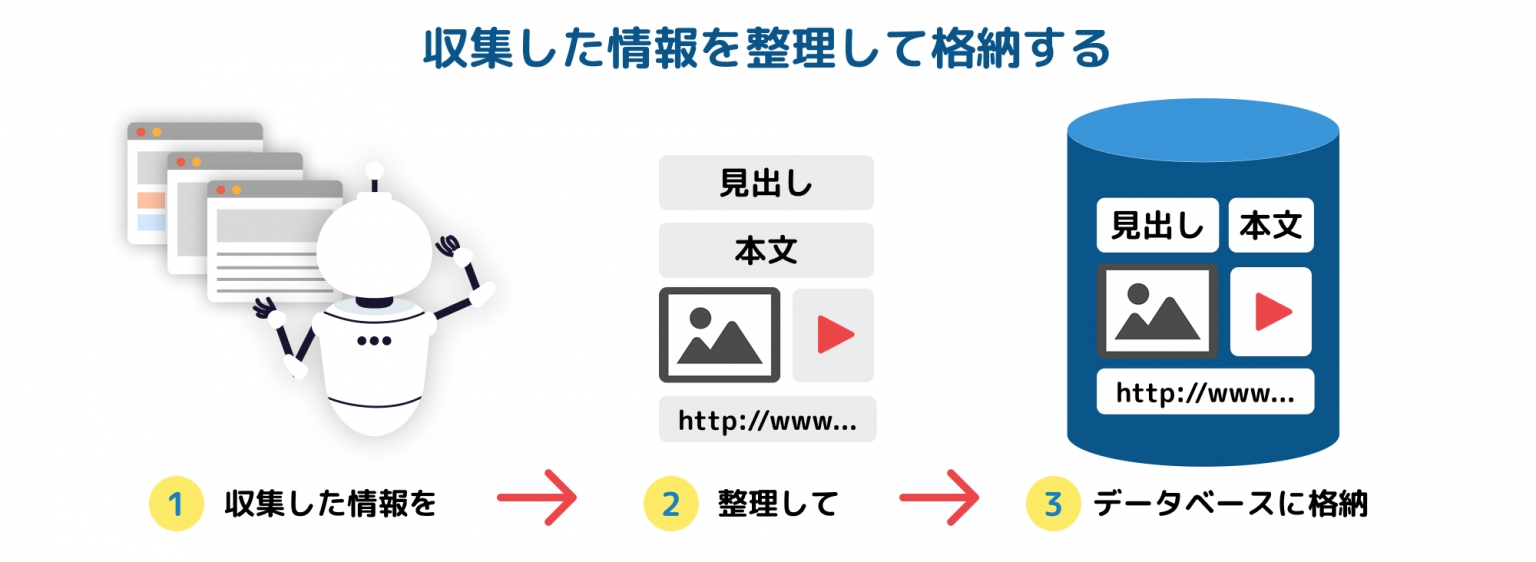
インデックス(集めた情報を登録する)
クロールで集めた情報を整理し、検索できるようにDBに登録する
入力したキーワードに関連するページを素早く見つけられるようにする
クローラーが取得したHTMLデータを分析する
ページ内の重要なキーワードを抽出し、内容ごとに分類
構造化された情報としてデータベースへ格納
ページの評価を行う
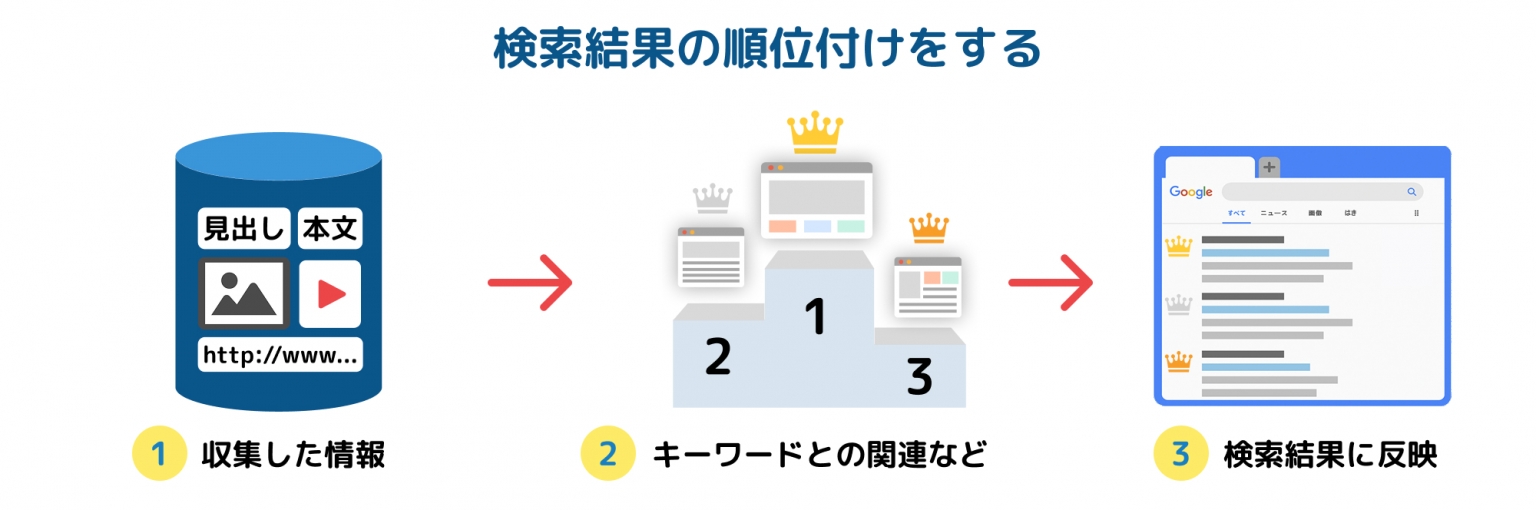
ランキング(検索結果の順番を決める)
インデックスに登録されたたくさんのウェブページの中から、
ユーザーが入力したキーワードと最も関係が深く、役立つと判断した順に
ページを並べて表示する
ランキングによって検索結果に表示される順番が決まるので、
ユーザーは知りたい情報にすばやくたどり着くことができる
3.ランキングの要素
| システム | 内容 |
| BERT | 単語の組み合わせによって、意味や意図がどのように変化するかを理解するAI |
| 重複除去システム | 似通ったページが複数あった場合、有用性の低いページを除外する |
| フレッシュネスシステム | 鮮度が重要なキーワードについては、ページ内情報の鮮度の高さを評価する |
| リンク分析システムとPageRank | ページ間のリンクを元に、どのページが有用かを判断する |
| ローカルニュースシステム | 関連性の高い地域のニュース情報を特定して表示する |
| オリジナルコンテンツシステム | 独自性の高いコンテンツが、単にそれを引用したものよりも検索上位に表示される |
| レビューシステム | 独自の分析や調査結果、専門家や愛好者が書いたコンテンツを高く評価する |
| サイト多様化システム | 1つのウェブサイトが検索結果の上位を独占しないようにする |
4.効率よく検索にヒットするには
インデックス登録に至らない要素(逆ならば登録されやすい)
ページのコンテンツの品質が低いもの
Robots meta ルールによってインデックス登録が禁止されるものい
ウェブサイトのデザインが原因でインデックス登録が困難なもの
検索エンジンに正しく登録してもらうためには、
質の高いオリジナルな情報を提供することが重要