実行例は「saka.mokumoku」の「Google Colabotry」環境に保存してある
1.事前準備
matplotlibを使って可視化する
「Work Shop」の「3大ライブラリー」のMatplotlibを参照
スライスを使ってデータを特定する
リストや文字列、タプル等のシーケンス型の一部を
インデックスを指定して取り出す
複数の数値をコロン(:)で区切って[ ]で囲う
a[start : stop : step]
step:何個ごとに抽出するか(デフォルト=1)
start:切り取りたい部分の開始(一番左)のインデックス
stop:切り取りたい部分の終わり(一番右)のインデックス
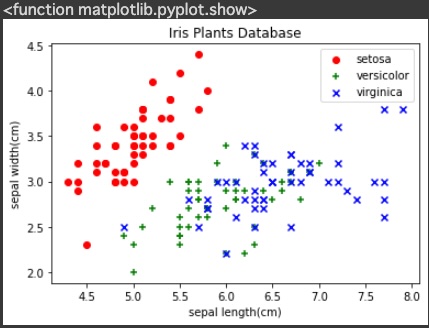
2.散布図の作成
x軸にはがく片の長さ、y軸にはがく片の幅をセット、散布図を描く
がく片の長さとがく片の幅だけで、特徴が現れる
3つのブロックが50㎝、100㎝で区切られる理由が分からない
import matplotlib.pyplot as plt
x = iris.data
y = iris.target
plt.scatter(x[:50, 0], x[:50, 1], color='r', marker='o', label='setosa')
plt.scatter(x[50:100, 0], x[50:100, 1], color='g', marker='+', label='versicolor')
plt.scatter(x[100:, 0], x[100:, 1], color='b', marker='x', label='virginica')
plt.title("Iris Plants Database")
plt.xlabel("sepal length(cm)")
plt.ylabel("sepal width(cm)")
plt.legend()
plt.show scatter命令について
scatterの第1引数がX軸、第2引数がY軸
引数で線の色(color='')やマーカーの種類(marker='')、インデックス(index='')なども指定できる
3.機械学習
TensorFlowとKerasをロードする
乱数のシード値を固定して並べ替える
引数は実数であれば良い、1に設定する
TensorFlowの重みの設定が固定される
idxr = [k for k in range(Ndata)]はリスト内包表記という
既存のリストから新しいリストを作ること
分かりやすく分解すると下記のようになる
idxr = []
for k in Ndate
idxr.append(k)
print文でリスト内に0から149までの数値が格納されていることを確認する
random.shuffle(idxr)よって先ほどのリストの中身をシャッフルし、
print(idxr)で中身がランダムに再配置されたか確認する
#
#TensorFlowとKerasをロードする
#
import tensorflow as tf
from tensorflow import keras
print(tf.__version__)
#
#シード値を設定する
#
tf.random.set_seed(1)
#
#データをランダムに並べ替える
#
import random
random.seed(12345)
Ndata = len(iris.data)
print(f"Ndata={Ndata}")
idxr = [k for k in range(Ndata)]
print(idxr)
random.shuffle(idxr)
print(idxr) データを分割する
訓練データと検証データを半分、半分に分割する
print(f"# of training data = {Ndata_train}")と
print(f"# of validation data = {Ndata-Ndata_train}")で
それぞれ訓練データと検証データの数を出力する
train_data = iris.data[idxr[:Ndata_train]]の行では訓練データを、 train_labels = iris.target[idxr[:Ndata_train]]の行では訓練データの教師ラベルを
スライスを使って、idxrの0~74番目を各iris.dataとiris.targetに対応させ
train_dataとtrain_labelsに代入する
val_data = iris.data[idxr[Ndata_train:]]の行では検証データを、
val_labels = iris.target[idxr[Ndata_train:]]の行では検証データの教師ラベルを
スライスを使って、idxrの75~149番目を各iris.dataとiris.targetに対応させ
val_dataとval_labelsに代入する
Ndata_train=int(Ndata*0.5)
print(f"# of training data = {Ndata_train}")
print(f"# of validation data = {Ndata-Ndata_train}")
train_data = iris.data[idxr[:Ndata_train]]
train_labels = iris.target[idxr[:Ndata_train]]
val_data = iris.data[idxr[Ndata_train:]]
val_labels = iris.target[idxr[Ndata_train:]] ニューラルネットワークを作成する
KerasのSequentialというクラスを使ってニューラルネットワークを作成
4次元(がく片の長さ、がく片の幅、花弁の長さ、花弁の幅)のデータから
3次元(setosa, versicolor, virginica)のラベルへ層が構成されている
中間層は2層でユニット数(中間層の次元)は10、
Denseで設定したため全結合層になっている
modelには、keras.Sequentialから作成したインスタンスが入っており、
これを使用してデータを学習させることが可能になる
model = keras.Sequential([
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(10, activation='relu'),
keras.layers.Dense(10, activation='relu'),
keras.layers.Dense(3, activation='softmax')
]) 機械学習の準備を行う
modelインスタンスのcompileメソッドを使って学習の設定を行う
compileには引数が3つ
optimizer:最適化手法を設定する
今回はSGDに設定
loss:損失関数を設定する
今回はsparse_categorical_crossentropyに設定
metrics:評価関数を設定する
accuracyを入れておけば問題ない、評価関数を設定しても良い
model.compile(optimizer='SGD',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']) 機械学習を行う
modelインスタンスのfitメソッドを使うことで学習を行う
fitの引数に
訓練データとそれに対応する訓練データのラベルを代入する
オプションとして他に4つの引数を使っている
validation_data:検証用データをタプルにして渡す
(val_data, val_labels)を設定する
epochs:エポック数を設定、デフォルトは1
30に設定するしている
batch_size:バッチサイズを設定、デフォルトは32
ミニバッチのサイズはNdata_train//10によって7つだが、
この数字に特に意味はない
verbose:ログ出力の設定、デフォルトは1
0だとログが出ない
正の値だと細かいログが出力される
負の値だとepoch数のみ表示される
training_history = model.fit(train_data, train_labels,
validation_data=(val_data, val_labels),
epochs=30,
batch_size = Ndata_train//10,
verbose=1) 結果を評価する
履歴を見る
fitの返り値をtraining_historyに代入し、中身を見る
大量に表示されるが履歴はhistoryに格納されている
出力結果に'accuracy':とあることからdict型のリストである
辞書のキーに何が入ってるのか確認するためにkeysメソッドを使う
4つのキーで構成されていることがわかる
val_accuracy:検証データに対する精度の値
loss:訓練データに対する損失関数の値
accuracy:訓練データに対する精度の値
val_loss:検証データに対する損失関数の値
dir(training_history)
training_history.history
training_history.history.keys() 精度を確認する
訓練データに対する精度の値と検証データに対する精度の値を確認する
訓練データに対する精度の値が79%
検証データに対する精度の値が73%
print("traininig")
print(training_history.history['accuracy'][-1])
print("validation")
print(training_history.history['val_accuracy'][-1]) 損失関数と精度の履歴について散布図で可視化する
損失関数の散布図は対数軸にするためにplt.semilogyを使う
精度の散布図はplt.ylimを使ってy軸の範囲を0~1.1に設定する
# 訓練データに対する損失関数のプロット
y=training_history.history['loss']
x=range(len(y))
plt.semilogy(x,y,label="loss for training")
# 検証データに対する損失関数のプロット
y=training_history.history['val_loss']
x=range(len(y))
plt.semilogy(x,y,label="loss for validation",alpha=0.5)
plt.legend()
plt.xlabel("Steps")
plt.show()
# 訓練データに対する精度のプロット
y=training_history.history['accuracy']
x=range(len(y))
plt.plot(x,y,label="accuracy for training")
# 検証データに対する精度のプロット
y=training_history.history['val_accuracy']
x=range(len(y))
plt.plot(x,y,label="accuracy for validation")
plt.legend()
plt.xlabel("Steps")
plt.ylim(0,1.1)
plt.show()4.結論
最終的な訓練データの正答率は79%、検証データの正答率は73%
アヤメは3種類なので当てずっぽうの33.3%よりは高い精度
散布図では損失関数が減少すると分類精度は上昇する、負の相関が見られる