1.教師あり学習
データと正解を対応させて学習し、
データだけを与えて正解を予測させる仕組み
回帰問題・・・数値を予測する
分類問題・・・種類を予測する
<事例研究>
| 基本情報 | y=ax+100 | y=ax+100 | |||||||
| 気温 | 売上本数 | 気温20度 売上予想 | 基本情報との差 | 差の2乗 | 気温30度 売上予想 | 基本情報との差 | 差の2乗 | ||
| 12 | 342 | 340 | -2 | 4 | 460 | 118 | 13924 | ||
| 5 | 203 | 200 | -3 | 9 | 250 | 47 | 2209 | ||
| 0 | 100 | 100 | 0 | 0 | 100 | 0 | 0 | ||
| 1 | 120 | 120 | 0 | 0 | 130 | 10 | 100 | ||
| 4 | 182 | 180 | -2 | 4 | 220 | 38 | 1444 | ||
| 13 | 361 | 360 | -1 | 1 | 490 | 129 | 16641 | ||
| 11 | 319 | 320 | 1 | 1 | 430 | 111 | 12321 | ||
| 19 | 46639 |
売上本数=y、気温=x、xの増減によりyが決まる
気温0度の時、100本売れているのでy=aX+100の式が成り立つ
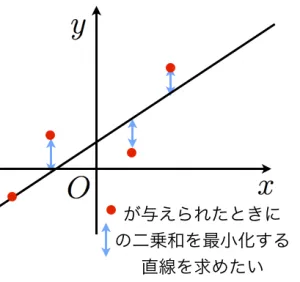
最初にa=20として、売上げ予想を求め、誤差の2乗の合計が19
次にa=30として、売上げ予想を求め、誤差の2乗の合計が46,639となる
差にはプラスとマイナスがあるため2乗して数値を揃える
次々とaの値を設定し、誤差の合計が最も少なくなるaを選ぶ
aが決まれば、温度による売上本数の予測がつく
2.教師なし学習
データの特徴を基にグループに分ける仕組み
<事例研究>
3人の注文履歴は以下の通り
| コハダ | 中とろ | ハッキ貝 | 車海老 | 赤身 | 雲丹 | しめ鯖 | 大トロ | 玉子 | |
| Aさん | 1 | 1 | 1 | 1 | 1 | ||||
| Bさん | 1 | 1 | 1 | 1 | 1 | ||||
| Cさん | 1 | 1 | 1 | 1 | 1 |
他人と重なった注文をした人を確認する
| コハダ | 中とろ | ハッキ貝 | 車海老 | 赤身 | 雲丹 | しめ鯖 | 大トロ | 玉子 | |
| Aさん | 1 | 1 | 1 | ||||||
| Bさん | 1 | 1 | 1 | ||||||
| Cさん | 1 | 1 | 1 | 1 | 1 |
Dさんは現在こういった注文状況
| コハダ | 中とろ | ハッキ貝 | 車海老 | 赤身 | 雲丹 | しめ鯖 | 大トロ | 玉子 | |
| Dさん | 1 | 1 | 1 | 1 |
DさんがAさん、Bさん、Cさんと同じものを頼んだ品を数える
Aさんと2品、Bさんと3品、Cさんと4品が同じ
そうするとDさんは次に選ぶのは
Cさんが選んだモノの中から残りの1個を選ぶだろう
3.強化学習
「教師あり学習」と似ているが正解がない
試行錯誤しながら適切な行動に報酬を与え、繰り返し学習する仕組み
4.業務へ応用する
(1)計画の立案
どのような目的で機械学習を使うのかを決める
(2)データの収集
必要なデータと収集方法を決める
関連性の低いデータ、収集が難しいデータ、制御できないデータ等は除外する
(3)データの前処理
前処理用のプログラムを用意する
データ内容の確認、欠損値の確認、データ型の変換、説明変数の作成と削除、データの正規化等を行う
(4)モデルの構築、学習、評価
機械学習用のモデル(プログラミング)を作成する
データの分割:
モデル評価用に2割~3割、残りを機械学習用にする
機械学習用の中から性能検証用に2割~3割を当てる
モデルの選択:
多くのモデルの中から選択する(参照:選択基準表)
モデルの学習、評価、調整、を繰り返す
選択したモデルで学習用データを使って学習する
学習済みのモデルの性能を性能検証用データを使って検証する
パラメータ変更、モデル変更等を行い目的達成まで繰り返す
最後に評価用データを使って最終評価を下す
(5)業務への導入
導入形態の検討:
要件を整理し、ユーザーの操作性等も検討する
環境の調査:
プログラム実行に必要な資源(ハード、ソフト)を調達する
既存システムとの調整:
既存システムの改修や新規作成等を調整する
導入効果測定用のロギング機能を組み込む
(6)運用、モデルの改善
予測精度は徐々に劣化するので、モデルの再学習を行う
<資料> scikit-learn(サイキット・ラーン)より引用
