「仕組み」について具体的な記述ができていないので、後日対応します
1.VAE(Variational Autoencoder)
ディープラーニングを活用した画像生成モデル
AIの学習用データから特徴を学び取り、
その特徴をもとに「学習用データと似ている新しいコンテンツ」を
生成する
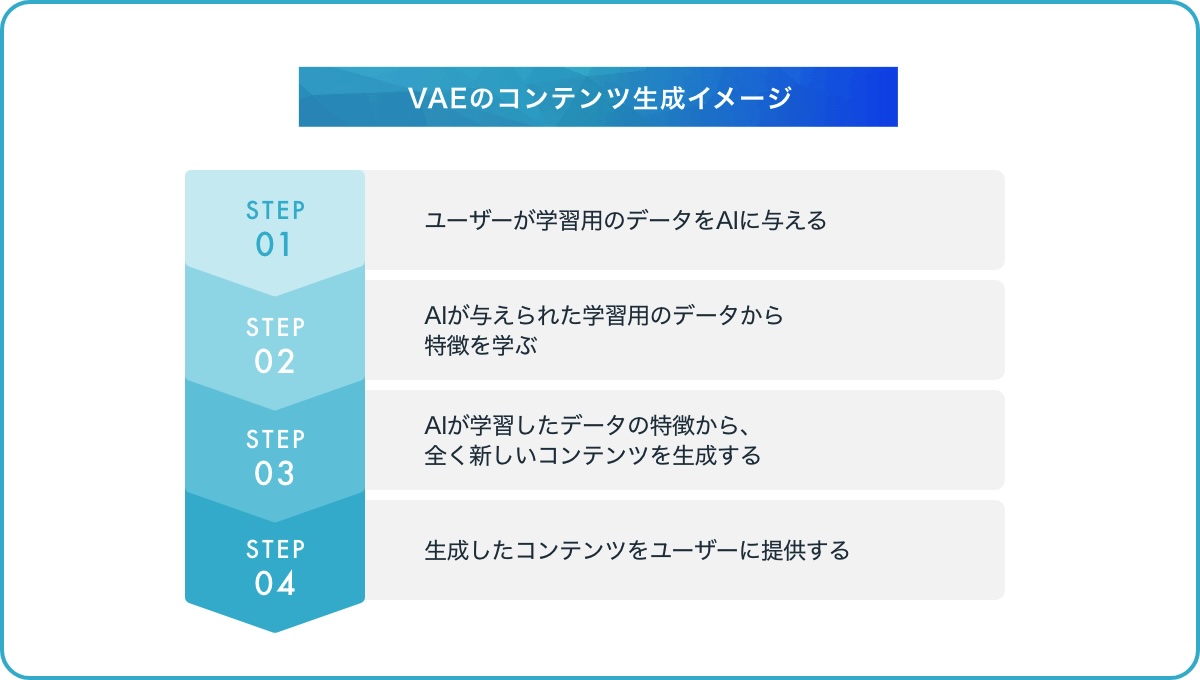
処理概要
ユーザーが学習用のデータをAIに与える
AIが与えられた学習用のデータから特徴を学ぶ
AIが学習したデータの特徴から、全く新しいコンテンツを生成する
生成したコンテンツをユーザーに提供する
利用上の特徴
特定の傾向を持つ複数の作品を学習し、その作風に近い作品を生み出す
画家の作品を学ばせ、画家の特徴を持った新しい絵を生み出す
複雑性の高い画像の特徴を捉え、構造が複雑な製品の異常検知
2.GAN(Generative Adversarial Networks)
ディープラーニングを活用した画像生成モデル
Generator(ランダムに作成されたデータ)
Discriminator(学習用の正しいデータ)
2つのネットワークを競わせながら学習し、精度の高い画像を生成する

処理概要
ランダムなノイズからGeneratorを生成する
正しいデータである「Discriminator」を用意する
GeneratorとDiscriminatorを比較して、Generatorが本物かどうか判定する
1~3を繰り返し、Generatorの精度を高める
十分に精度の高まった画像を出力する
利用上の特徴
解像度の低い画像から解像度の高い画像を生成する
テキスト入力で全く新しい画像を生成する
3.拡散モデル
学習用の画像にノイズを追加し、画像からノイズを除去し、元画像を復元する
与えた画像にノイズを付加し、元の画像を復元することを繰り返す
「Stable Diffusion」や「DALL-E2」などに採用されている
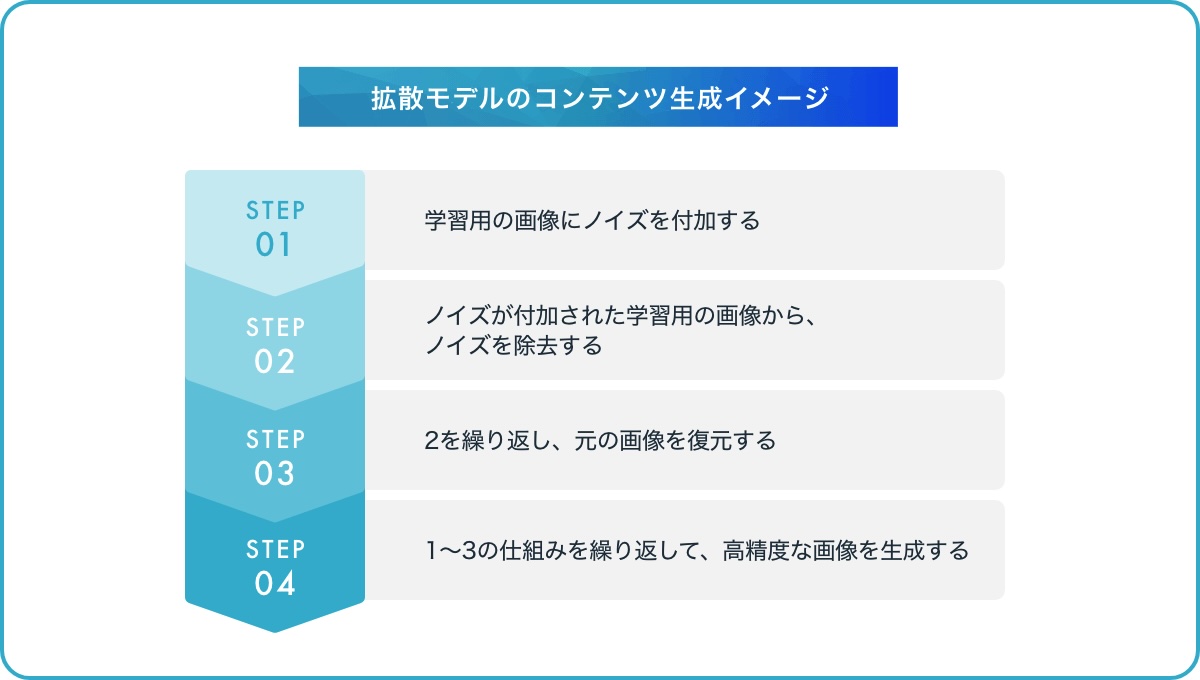
処理概要
学習用の画像にノイズを付加する
ノイズが付加された学習用の画像から、ノイズを除去する
2を繰り返し、元の画像を復元する
1~3の仕組みを繰り返して、高精度な画像を生成する
利用上の特徴
GANよりもさらに高解像度な画像を生成する
4.GPT-3
OpenAIが開発した言語モデル
約45TBもの膨大なテキストデータを学習し、
ある単語の次に記述される別の単語の候補を高精度で予測する

処理概要
ユーザーがテキストボックスに質問を記述し、入力・送信する
AIは質問の内容を解析して、最適な回答を導き出す
AIは回答を出力し、ユーザーに伝える
利用上の特徴
長文の要約やリサーチ時間の短縮化
新たなアイデアの創出